Identificación de Buyer Persona con Inteligencia Artificial

¿Puede la Inteligencia artificial ayudarnos a identificar mejor a nuestros Buyer Persona?
En este post, me gustaría abordar una pregunta que lleva ya tiempo encima de mi mesa. El uso de la IA para mejorar la identificación y clasificación de contactos. Aquí va el problema y la hipótesis:
Problemática en el inbound Marketing.
El inbound Marketing como metodología se basa en la captación de contactos para su posterior maduración y acompañamiento en los diferentes viajes del comprador, con un proceso intermedio, la clasificación del contacto y una meta final, convertir contactos en clientes. Por razones de simplicidad no voy a entrar en desgranar todo el proceso, que seguramente ya conoces.
La problemática que estamos observando es que un alto porcentaje de sus contactos no tienen identificados sus Buyer Persona y/o que la identificación del BP es errónea y como consecuencia genera una incorrecta contextualización y personalización de las acciones que realizan. A esto se suma que en los casos en los que sí se identifica, ocurren al final del viaje del comprador ( etapa de decisión).
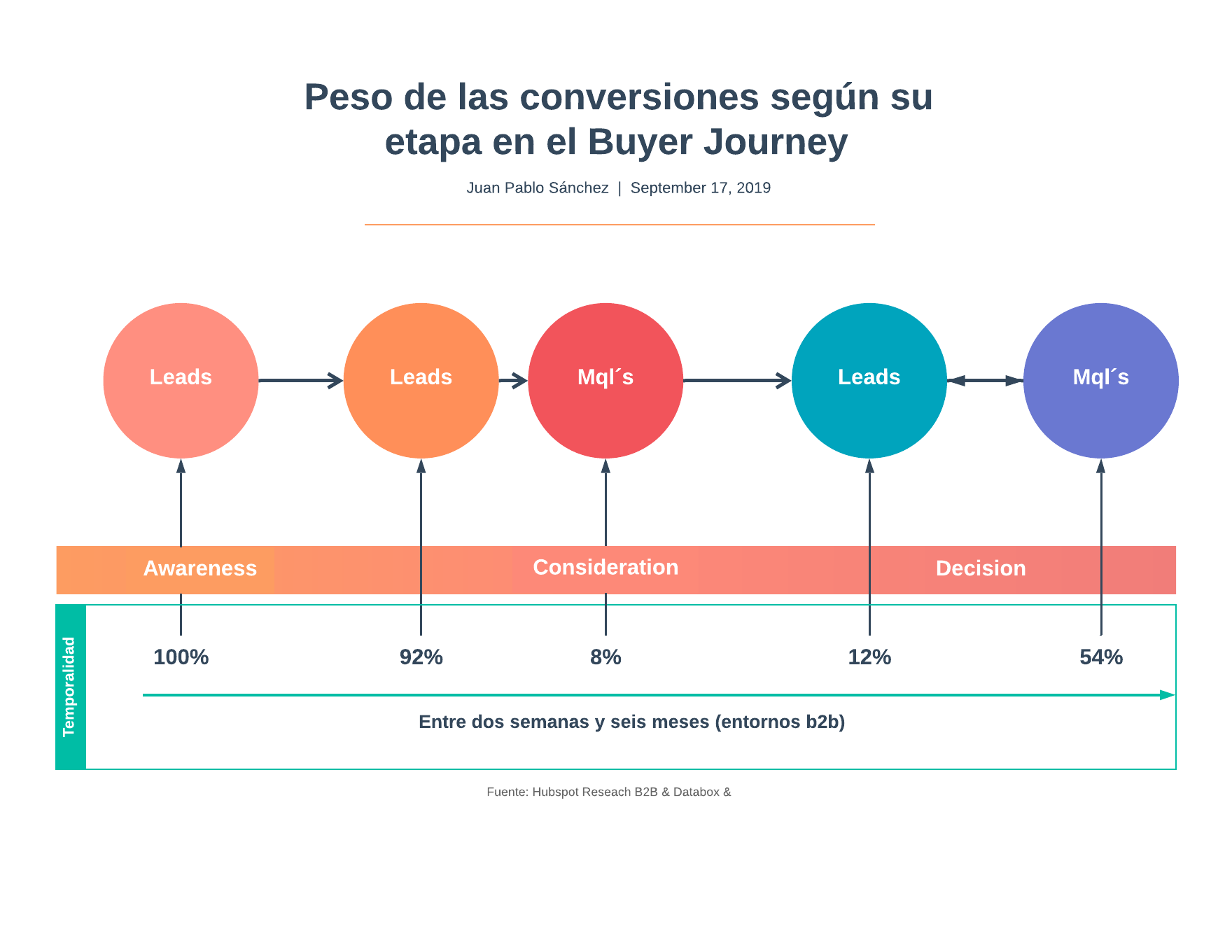
Las principales consecuencias de esto son:
- Aumento de la fricción del cliente en su viaje del comprador.
- Aumento del tiempo total en el viaje del comprador.
- Perdida de Engagement del usuario.
Formulando la hipótesis
¿Qué pasaría si fuéramos capaces de identificar correctamente a que Buyer Persona pertenecen nuestros nuevos contactos con la primera conversión? (para así poder personalizar y contextualizar su viaje del comprador).
- ¿Aumentaría el nivel de engagement?
- ¿Disminuiría el tiempo total del viaje del comprador?
- ¿Disminuiría la fricción del cliente en su viaje del comprador?
.png?width=1760&name=Copia%20de%20Viwomail%20CRO%20-%20Inbound%20Sales%20(4).png)
Planteando el experimento
Vamos a partir del siguiente supuesto,
Tenemos un visitante corporativo que se encuentra en la etapa de Awareness y después de leer algunos post, accede a una landing page, lee la oferta de la misma y procede a rellenar el formulario compuesto por tres campos.
Convirtiéndose en un contacto clasificado como lead que esta en nuestro portal de HubSpot. Los campos obtenidos en la conversión son:
- El email corporativo,
- El nombre
- Apellido
El objetivo que estamos buscando es ser capaces de predecir si se trata de alguno/s de los Buyer Persona/s actuales. Para ello vamos a necesitar disponer de un conjunto de datos con una muestra representativa así como una alta calidad de los datos. Así mismo tomamos como valida la correlación directa entre un Marketing Qualified Lead y un Buyer Persona.
Estamos buscando encontrar correlaciones que puedan existir entre esos buyer persona y las dimensiones de datos que podamos obtener. Un primer análisis nos va a llevar a poder disponer de +100 puntos de datos procedentes de HubSpot, un número que a priori no es demasiado manejable, pero que podemos agrupar por su dimensionalidad con el objetivo de minimizarlo.
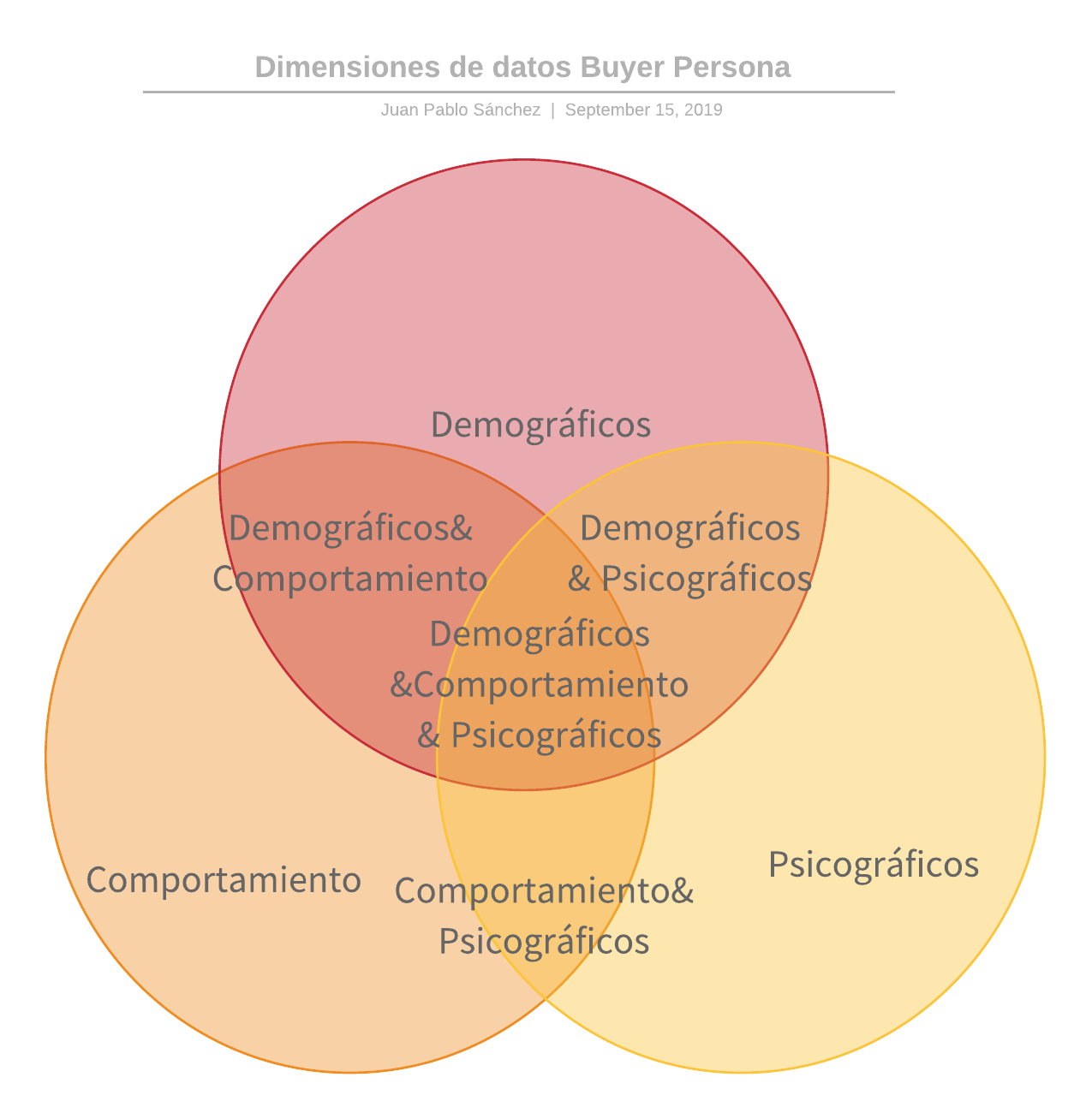
Aplicamos un diagrama de VENN para que nos permita entender que tienen en común y por tanto que estrategia de agrupamiento de datos seleccionar. Ahora, si entramos dentro de cada dimensión, veremos que dentro de la misma nos podemos encontrar con algo parecido a esto:
.png?width=1163&name=Diagrama%20Proceso%20Ciencia%20de%20datos%20para%20el%20Buyer%20Persona%20-%20Pa%CC%81gina%206%20(2).png)
Por razones de simplicidad de este post, no voy a entrar en analizar cada una de las dimensiones y su fuerza correlativa con el Buyer Persona (si alguien esta interesado puede invitarme a un cafecito y lo hablamos con mucho gusto!.). simplemente comentaros que es un proceso de refinado muy largo donde en función de la serie histórica que tenga cada cliente a analizar, nos podemos encontrar con desequilibrios importantes en las series de datos, como por ejemplo un % muy alto de Buyer Persona clientes, que su fuente de origen es offline y por tanto toda la dimensión de comportamiento digital seguramente este sesgada. Esto significa que si aplicamos solo la dimensión de comportamiento ( huella digital), nos vamos a encontrar con un solapamiento de datos y alineaciones multiples como se puede apreciar en esta clusterización usando el algoritmo T-SNE.
.png?width=997&name=dataview-vis%20(34).png) El gráfico muestra 1.324 contactos pertenecientes a dos Buyer Persona y un solapamiento de los registros bastante atomizado. Cuando deberíamos ver a priori dos clusters que deberían corresponder con los dos Buyer Persona, si estuviéramos en el mundo ideal. Pero es que, ademas de esto, sí eliminamos el canal offline, seguiremos teniendo el mismo problema.
El gráfico muestra 1.324 contactos pertenecientes a dos Buyer Persona y un solapamiento de los registros bastante atomizado. Cuando deberíamos ver a priori dos clusters que deberían corresponder con los dos Buyer Persona, si estuviéramos en el mundo ideal. Pero es que, ademas de esto, sí eliminamos el canal offline, seguiremos teniendo el mismo problema.
¿Qué esta pasando?..
Bueno, cada caso es un mundo, pero a nivel general, si categorizáramos correctamente todos los puntos de datos, veríamos que la dimensión de la que disponemos mayor cantidad es la del comportamiento digital y que la calidad de los datos demográficos y/o psicográficos es incompleta en una gran mayoría. Por lo que solo contamos con datos de comportamiento digital.
SI analizamos en profundidad los datos de comportamiento digital, nos daremos cuenta que son en su mayoría datos numéricos globales, como son páginas vistas, conversiones realizadas, emails abiertos, etc.. y una cantidad mínima de datos textuales, como son primera y última página vista, fuentes de origen, etc.. sin embargo, no son suficientes para poder determinar un comportamiento claro como hemos visto en la clusterización T-SNE y como podemos observar en este gráfico comparativo de Buyer Persona/s.
.png?width=1820&name=dataview-vis%20(16).png)
Resumiendo, los datos de comportamiento que nos ofrece HubSpot, no son un indicador que nos ayuden a determinar un Buyer Persona por sí solos.
¿Entonces, qué determina el Buyer Persona?
Pues como hemos visto en el gráfico de VENN, un pequeño conjunto de datos de las tres dimensiones ( para ello deberemos enriquecer y seleccionar cada punto de dato) y podemos demostrarlo claramente cuando esta selección se muestra en un gráfico de T-SNE.
.png?width=1320&name=dataview-vis%20(37).png) ( Fuente: sample 165 registros, refinados y enriquecidos provenientes del mismo dataset usado en el gráfico anterior)
( Fuente: sample 165 registros, refinados y enriquecidos provenientes del mismo dataset usado en el gráfico anterior)
Eureka!, esto ya es otra cosa, vemos agrupaciones de datos sin solapamiento y con una clusterización muy definida siendo indicadores suficientemente claros, como para indicarnos que el uso de las tres dimensiones determina el Buyer Persona. Por último, procedemos a identificar a los Buyer Persona.

Vemos un agrupamiento de los Buyer Persona, bastante definido y podemos sacar las siguientes conclusiones:
- Aunque parezca poco creíble, los datos de comportamiento no estan aportando una diferenciación de Buyer Persona. ( en el próximo post abordaré este problema)
- Se necesitan datos demográficos y psicográficos para poder diferenciar correctamente los Buyer Persona.
- El uso de un pequeño conjunto de datos es suficiente para poder determinar un BP. Obteniendo mejores resultados cuando mezclamos las tres dimensiones.
- El enriquecimiento y calidad de los datos obtenidos por fuentes secundarias es crítico en todo este proceso.
- Un "cocktail de datos" adecuado, da como resultado una categorización cuasi "perfecta"
Preparando y entrenando a la Inteligencia Artificial
Ya hemos visto que podemos identificar por medio del enriquecimiento de datos a nuestros Buyer Persona.
Ahora toca el proceso final, es decir, tenemos que volver a retomar nuestro experimento inicial y realizar diferentes iteraciones. Al ser una categorización, me he centrado en algoritmos de clasificación multivariable, clustering y por último redes neuronales.
Veamos los resultados con la clasificación multivariable donde obtenemos un 79,34% de precisión, más que correcto, vamos. Sin embargo, creo que tenemos margen para subir al estar trabajando con datos desequilibrados ( muchos menos buyer 2 que buyer 1) y procedemos a ver qué ocurre con otros algoritmos de clusterización o por último con una red neuronal.
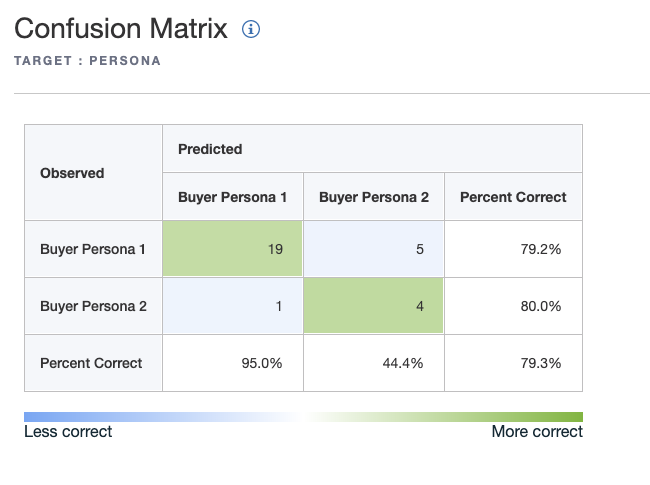
fuente ( N=145 contactos. split 80-20)
Al cabo de unas iteraciones hemos obtenido un 87,6% de predicción con un modelo de redes neuronales.
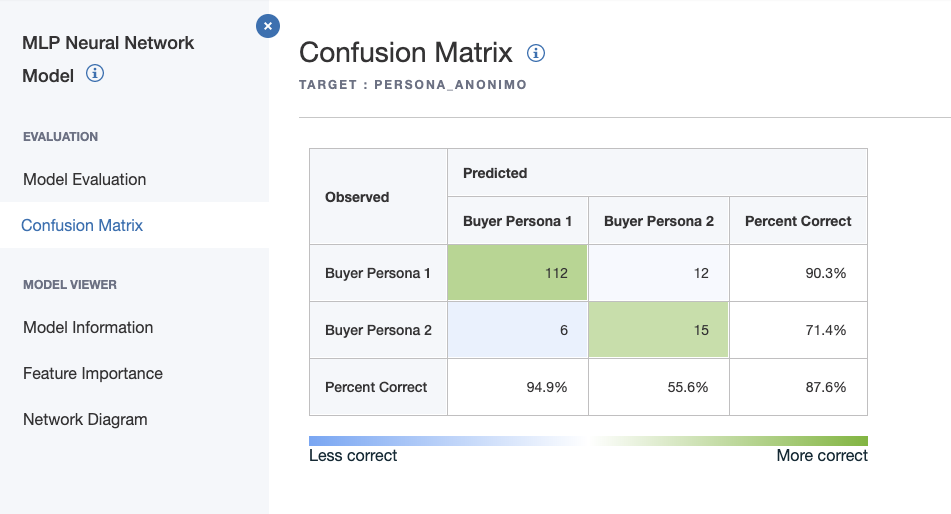
fuente (n=145 iteraciones red neuronal )
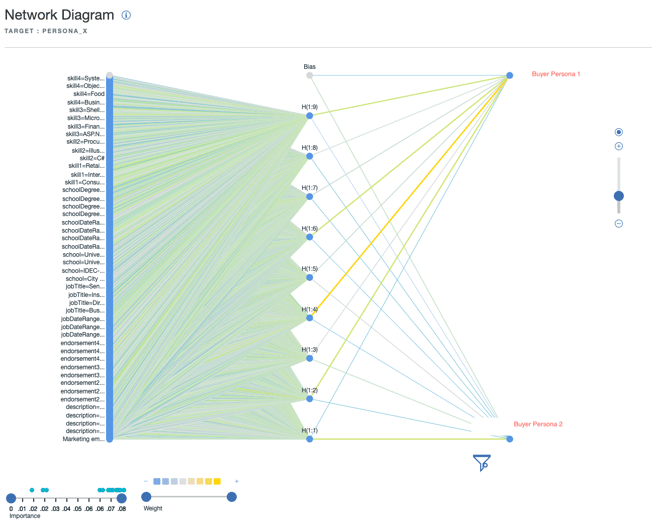
fuente ( n=145 iteraciones red neuronal )
Optimizando el aprendizaje de redes neuronales
El resultado de la red neuronal después de seguir optimizándola durante un tiempo nos ha dado un 100%. ;) Eso sí, somos conscientes que hemos trabajado sobre un sample de 145 registros sobre el total de 1.234 disponibles y este 100% debemos tomarlo como ir a ganar una competición de Kaggle.
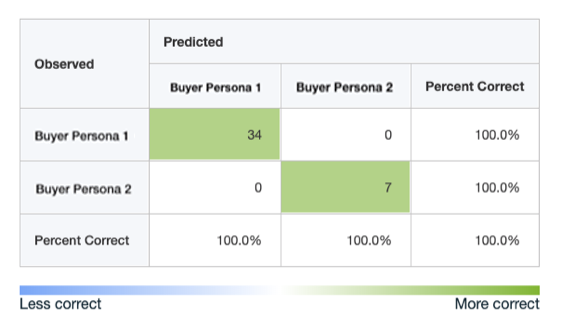
Conclusiones
Con este pequeño experimento, creo que hemos demostrado como es posible realizar un algoritmo de IA que permita identificar y categorizar correctamente de manera temprana contactos nuevos a Buyer Persona, dicho de otro modo cualificar leads en MQL´s. Eso sí, creo que la clave de todo esto, está, en la capacidad de poder enriquecer los leads con datos secundarios de manera automática ya que sin esto no habrá algoritmo que sea capaz de acertar.
Yo me pregunto,...
Si tuvieras la capacidad de saber en 10 minutos de todos tus leads, cuantos son MQL´s sin necesidad de esperar a nutrirlos o que por ellos mismos maduren, ¿pagarías por ello?
¿Qué podrás conseguir?
- Acortar drasticamente el tiempo de cualificación de leads.
- Optimizar tu inversión solo en aquellos contactos que sabes pertenecen a tu Buyer Persona.
- Crear una experiencia del consumidor que se adapta a tu cliente ideal ya desde una etapa inicial de su viaje del comprador.
- Optimizar la creación y priorización de generación de contenido.
- Mejorar el perfil de tu Buyer Persona con insights reales.
- Personalizar la experiencia de tus Buyer Persona.
- Aumentar de manera exponencial el Retorno de inversión.
- Acortar el periodo necesario para que tu Inbound genere tracción y beneficios. ( al necesitar muchos menos contenidos)
- Reducción del coste de cualificación de MQLs. (Ejemplo)
Coste actual ( 40€=60€-20€) , CCMQL = Coste.MQL - Coste.Lead.
Coste de este sistema aprox. entre 30-15 euros por MQL. ( ahorro entre el 30%-70%).
Resumiendo, dejarás de pescar con red de arrastre y pasarás a pescar con caña y un barco con sonar de alta resolución, el cual te indica donde está el pescado y donde no.
¿Te interesan estos temas?
Agenda una reunión y hablemos

.webp?width=352&height=352&name=0_1%20(1).webp)

