Creación de Fast Tracks en la nutrición de leads y modelos de lead scoring predictivo.

Es increíble ver como el lead scoring se está convirtiendo en toda una tendencia en el mundo del inbound marketing. Cada semana se publican artículos sobre sus beneficios, diferentes formas de crearlos, mejores prácticas y algún que otro truco secreto con promesas de profeta de absenta negra. Sin embargo, no veo que se hable de cómo usarlo para ganar a tu competencia. Así que, si estás preparado, me gustaría compartir contigo una de las nuevas armas que tenemos en la agencia: el fast track para inbound marketing®.
¿Qué es esto del fast track?
Fast track es un término que se usa para identificar un proceso acelerado que normalmente está asociado a un cliente o a un cliente potencial. Su razón de ser es aumentar la velocidad y reducir la fricción en el viaje del comprador. Podemos ver numerosos ejemplos en el sector aéreo: el mostrador para clase preferente, el control de seguridad o el embarque en el avión.
Si tomamos el concepto, lo llevamos al mundo del inbound marketing y lo usamos a la hora de nutrir los leads, crearemos una serie de acciones que van a ayudar a que nuestros leads vayan más rápido en el proceso de nutrición y con una menor fricción del usuario.
¿Qué se necesita para tener un fast track ?
Para crear un fast track, necesitamos cumplir una serie de requisitos, sin los cuales es mejor que ni te plantees crear uno. Los requisitos son:
- Disponer de un buyer journey completo en cuanto a activos, es decir, tres pilas de contenido, una para cada etapa del buyer journey.
- Disponer de un mínimo de 100 contactos que no hemos conseguido por el canal de pago off-line, que son clientes (lifecycle = customers).
- Disponer de los workflows de nutrición de dicho buyer journey.
¿Cómo se construye un fast track?
El método para crearlo difiere según quien lo haga; nosotros en la agencia usamos un framework muy parecido a los procesos de ciencia de datos como este que os muestro aquí abajo:

Aunque en realidad acabamos haciendo iteraciones y se parece a este otro framework que no deja de ser una evolución de aquel.
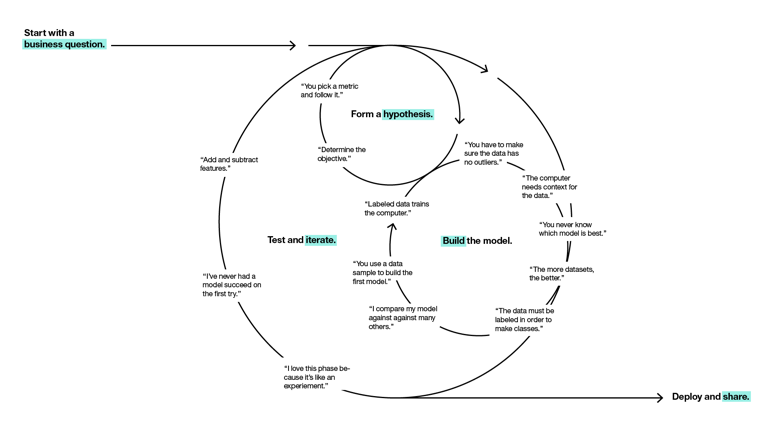
Por razones de simplicidad y para no alargar este post, me centraré en la siguiente hipótesis:
¿Qué pasaría si somos capaces de identificar un cliente potencial en nuestra base de datos y en caso afirmativo lo nutrimos con un contenido “acelerador”?, ¿se verá reducido el tiempo de viaje del comprador frente al actual?
Para la primera parte de la hipótesis usamos algoritmos de inteligencia artificial que analizarán de manera continua los datapoints que ha ido generando un contacto y producirá un lead scoring predictivo (lo he simplificado al extremo para no extenderme) con tres conjuntos de datos.
En la segunda parte de la hipótesis usamos aprendizaje profundo, pero en este caso para recomendarnos los contenidos que han contribuido o gustado a nuestros clientes. Este sistema es el que usaremos para alimentar los workflows del fast track. Si os lo cuento de forma técnica, diré que hemos usado un sistema de filtro colaborativo junto con un sistema híbrido de recomendación colaborativa.
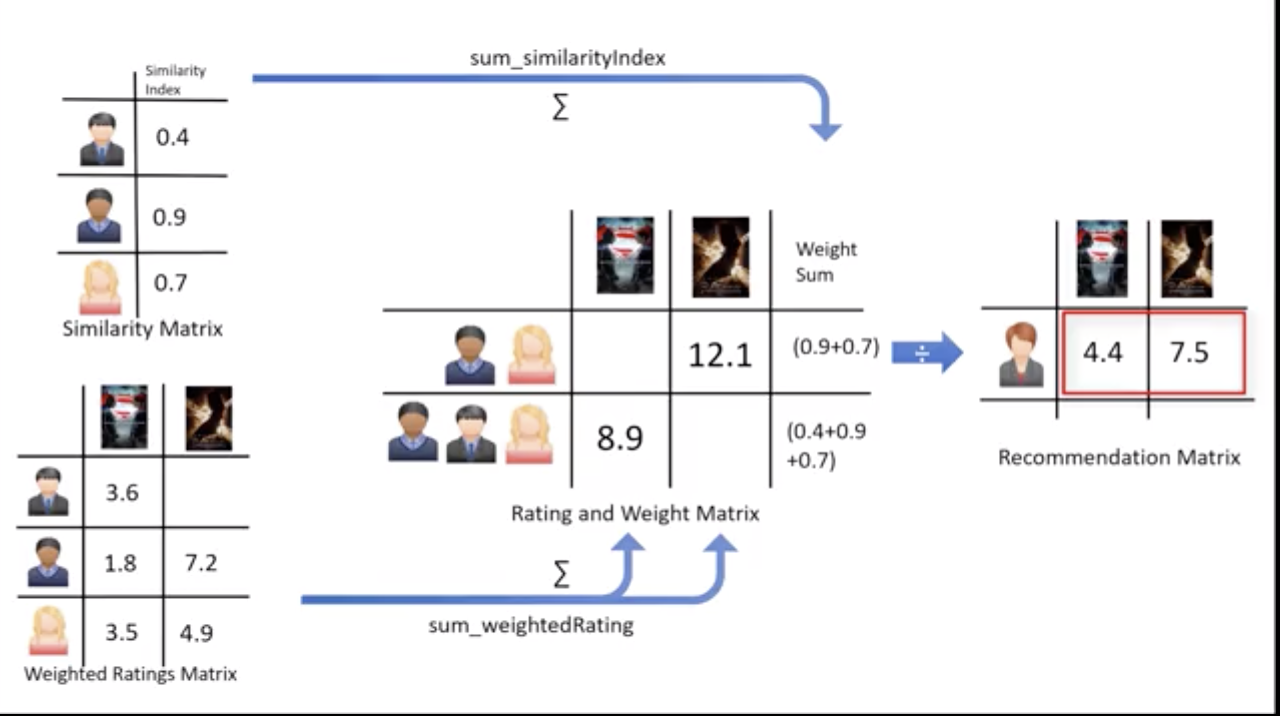
Os voy a enseñar el modelo de lead scoring que hemos desarrollado después de cinco años de experiencia en el ámbito del inbound y de investigar con más de diez millones de contactos.
Lead Scoring Predictivo Triédrico para entornos de B2B.
Se trata de un modelo basado en tres conjuntos de puntos de datos (datapoints) que nos permiten predecir la probabilidad de que un lead se convierta en un MQL, SQL o cliente.
Nuestro modelo tiene como principales características que es dinámico, encuentra una sobrepuntuación (over-scoring), se alimenta con fuentes de datos secundarias (datasets) y es capaz de detectar positivos ya con las primeras interacciones (con pocos datapoints de inicio).
Los tres conjuntos de datos que usamos son:
- Demográficos: Empresa, facturación, edad, código postal, etc.
- Comportamiento: Los datos de la huella digital, la tipología de consumo de contenido, la velocidad de consumo de contenido, etc.
- Hot triggers: Detección de visita de la página de producto, comparativa de productos, contacto, etapa del customer journey, etc.
Os muestro un ejemplo tomando los datos de cuatro contactos y mostrando el sumatorio de cada conjunto de datos:
| VID | Demográficos Score | Comportamiento Score | Hot Triggers Score |
| VID01 | 20 | 80 | 10 |
| VID02 | 40 | 10 | 80 |
| VID03 | 5 | 30 | 50 |
| VID04 | 0 | 50 | 70 |
Esta tabla contiene datos de cuatro contactos (VID=Visitor ID) y sus tres conjuntos de datos (Demográficos, Comportamiento y Hot triggers). Podemos ver que tenemos un VID01 muy activo (alta puntuación) en Comportamiento, pero no en sus otras dos categorías y, por otro lado, el VID04 no tiene puntuación en Demográficos y tiene una puntuación alta tanto en Comportamiento como en Hot triggers. Con esta información ya podríamos sacar alguna que otra conclusión, pero es mejor verlo en un gráfico en 3D.
-1-1.png?width=1133&name=dataview-vis%20(6)-1-1.png)
Podemos observar como el VID01, por mucho que tenga un scoring muy alto en comportamiento y bajo en demográfico, no lo tiene con respecto a hot trigger y por tanto vemos que se dibuja una figura plana, sin volumen.
En el otro extremo podemos ver la figura que ha generado el VID04, que tiene un scoring cero en demográfico, alto en comportamiento y muy alto en hot triggers.
¿Sabrías decirme qué VID es el que tiene más probabilidades de convertirse en cliente (y por tanto de ser candidato a un fast track )?
Seguramente, el sentido común te ha llevado a plantearte como solución que los contactos VID02, VID03, VID04 tienen probabilidades de convertirse en clientes y el VID01 no, al no tener puntuación en la dimensión de hot triggers. Es una respuesta que podríamos considerar válida si la votáramos en una reunión. Sin embargo, la respuesta correcta no es esa, sino que son aquellos VID cuya figura se aproxime o entre en el área de mis clientes.
¿Recuerdas que al principio del artículo te hablaba de la necesidad de cumplir unas premisas? Una de ellas es tener al menos 100 clientes en tu base de datos. Aquí es donde entran en juego, ya que el algoritmo toma como patrón de validación la figura geométrica que tenga cada contacto y, a partir de una concordancia determinada, da una puntuación final, donde 1 sería 100 % seguro y 0 %, cero certezas. Todo esto se realiza de manera continua en el tiempo, es decir, se recalcula continuamente según va alimentándose de datos nuevos con el fin de disparar cuanto antes un positivo para así poder introducirlo en un fast track.
¿Cómo debe ser un fast track?
Debe ser lo más rápido y eficiente posible para el contacto (¡ojo!, no para ti). Normalmente, un fast track serán uno o varios workflows que se activarán de manera automática en cuanto un contacto cumple el trigger designado.
No es indispensable, pero es muy útil si podemos contar con un journey mapping de nuestros clientes, ya que nos ayudará a dibujar el fast track.
Tomemos, por ejemplo, un journey mapping basado en el buyer persona de una agencia de inbound marketing. Más o menos es algo como este (si haces clic en la imagen, se ampliará).
Observamos que se podría empezar a trabajar el fast track a partir del paso de ID del problema que está valorado con -1 y por tanto genera fricción al usuario. Una forma de hacerlo sería con un flujo de conversión especial que le ofrezca la posibilidad de cualificarse como apto para un fast track y ayudarle a acortar su viaje del comprador. Si bien no estamos todavía usando nuestro sistema de inteligencia artificial, ayudamos a ese usuario y él nos ayudará a nosotros a clasificarlo cuanto antes para ofrecerle su mejor fast track.
A continuación, podríamos seguir usando el China customer journey para ir detectando puntos donde el fast track es útil para el usuario. Por ejemplo, vemos que en la etapa de presales el primer paso es una llamada, donde se ve si la agencia puede ayudar o no. Está valorada con un -2: genera fricción, por tanto, al usuario. Si queremos convertir este paso en un fast track que pueda usarse, podemos empezar a formular nuestras hipótesis. Un ejemplo de mejora fácil sería la creación de una agenda comercial con la máxima disponibilidad y que trabaje por encima de las otras que podamos tener. Es decir, estamos dando un servicio rápido y conveniente al usuario para reducir la fricción de este.
Un tercer ejemplo podría ser centrarnos en acelerar alguna de las etapas del buyer journey con un workflow inicial notificando a los usuarios que acaban de cumplir la condición de aptos que, a partir de ese momento, el contenido del blog le irá recomendando solo aquel que mejor se adapte a él. Esto se realiza usando smart content, un módulo a medida en HubSpot y la correspondiente integración de IBM Watson con nuestros algoritmos.
Ahora que ya hemos visto dos ejemplos concretos, y con el fin de no alargar más un post que ya es extenso, termino animando a que compartamos opiniones sobre este concepto, que en mi opinión tiene un gran potencial de crecimiento.



.webp?width=352&height=352&name=0_1%20(1).webp)